
Ask ChatGPT about your industry. Look at what it cites.
You'll see Wikipedia. You'll see Reddit. You'll see Forbes, G2, Mayo Clinic, YouTube transcripts, the occasional Substack. Brand blogs and product pages rarely appear in those citations.
This isn't a content quality problem. Plenty of brand content is good. It's not a domain authority problem either. Domain authority is an SEO metric, and AI systems don't behave like search engines. It's an infrastructure problem.
The citation pipelines AI systems learned to trust during training, and the retrieval indexes they query at inference time, were built for academic content. DOIs, citation files, repository deposits, structured metadata. Commercial content can borrow that infrastructure. The brands already doing it, mostly by accident, are showing up in places the rest of marketing can't.
That borrowed infrastructure has a name: Academic Citation Infrastructure, or ACI. This article is the accessible version. The formal methods paper documents the pattern, analyzes the mechanism, and proposes a controlled experiment for validation. The ACI Playbook is the operational template.
Why does ChatGPT cite Wikipedia more than your blog?
Three reasons, all mechanism-level.
One: AI systems were trained on content that flows through academic pipelines. Common Crawl, the foundation dataset for most LLMs, contains roughly 5 billion crawled pages. Wikipedia is in there. So is every Zenodo deposit, every arXiv preprint, every Crossref-registered DOI, every OpenAIRE-aggregated record. The infrastructure that makes academic content findable by humans also made it findable by the crawlers that built the training corpus.
Two: AI evaluation is influenced by source framing. A 2025 study published in Science Advances ran 192,000 assessments across 4,800 statements and 24 topics, varying only the source label attached to identical content. Evaluation outcomes shifted systematically. Identical text labeled as coming from one type of source got treated differently than the same text labeled as coming from another. The strongest effects clustered around academic vs. non-academic framings. AI systems aren't neutral about where a claim appears to come from.
Three: AI search uses query fan-out, and academic infrastructure puts you in more sub-queries. When you ask ChatGPT a question, it doesn't run one search. It decomposes the question into multiple sub-queries and searches concurrently across multiple data sources. AirOps' analysis of ChatGPT citations found that 32.9% of cited pages appeared only in fan-out sub-query results, not the original prompt. A piece of content with a DOI is indexed in DataCite. The same content, mirrored on Zenodo, gets a Zenodo landing page. If it's harvested by OpenAIRE, it gets that index too. Each of those is a different surface that can win a different sub-query.
Brand blogs aren't indexed in any of those pipelines.
The pattern is already in practice
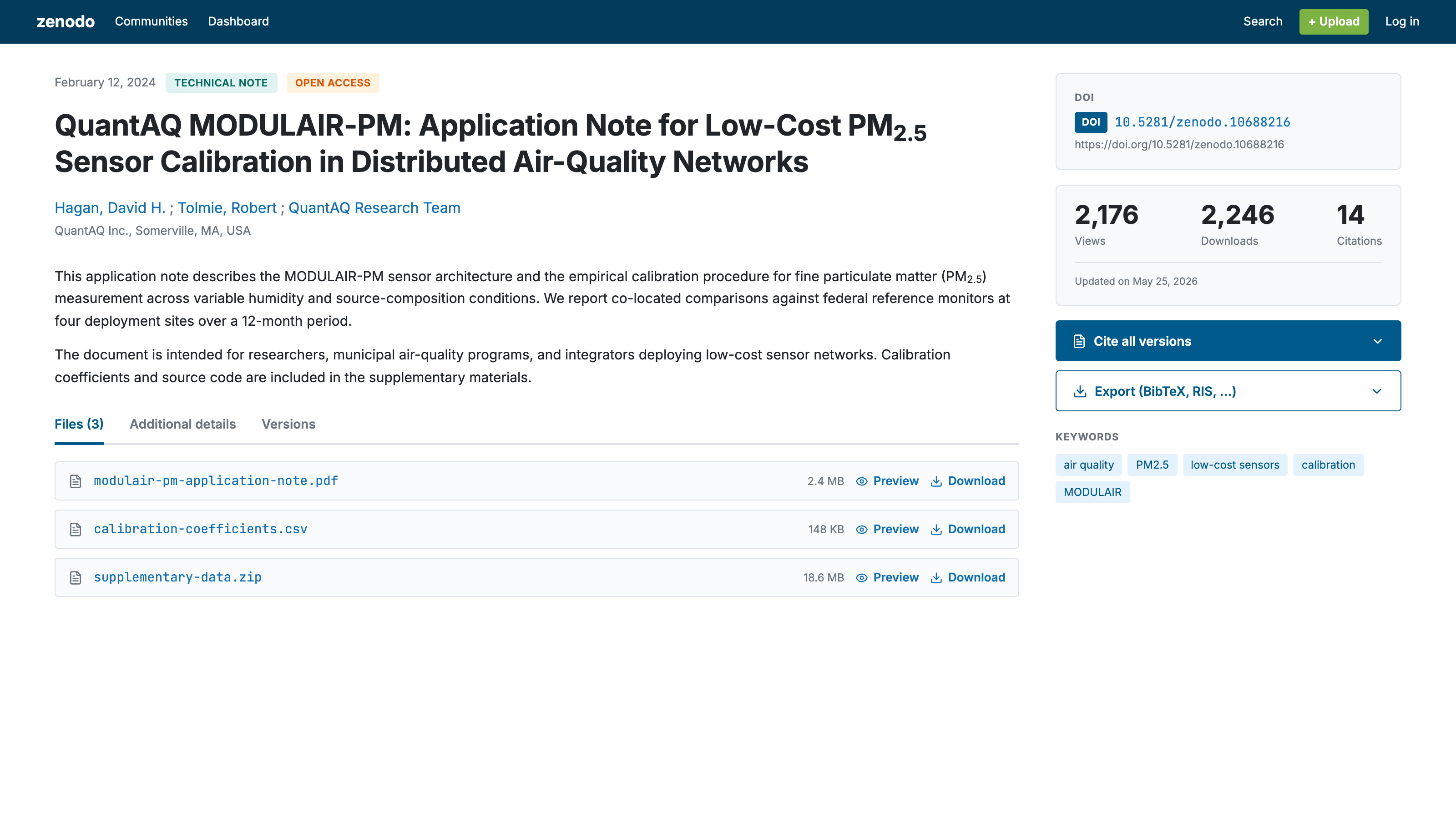
Commercial entities are depositing non-academic content on academic repositories. Most aren't doing it for GEO. They got there by other paths (defensive publication, regulatory submission, an internal scientist who likes Zenodo). The citation infrastructure works the same regardless of why it's there.
A few examples from a catalog of fifteen-plus documented in the methods paper:
- QuantAQ, an environmental sensor company, deposited a product application note on Zenodo with a DOI. It has accumulated 2,176 views and 2,246 downloads.
- Pensive Beauty, a skincare brand, posted a product technical note. 4,257 views.
- Berkeley Research Group, a consultancy, has multiple white papers on SSRN with DOIs. The pricing-model paper has 918 abstract views and 147 downloads; the Monte Carlo paper has 2,225 abstract views and 690 downloads.
- Cyberhare Solutions, an AI-detection vendor, deposited a defensive disclosure white paper. 111 views, 138 downloads.
- Digital Science put an Open Data report on Figshare.
- McKinsey Global Institute maintains an Academia.edu institutional profile.
None of these are research papers in the conventional sense. They're commercial deliverables (product notes, white papers, technical disclosures) wearing scholarly infrastructure. And they're racking up views, downloads, and indexing positions in pipelines their authors' marketing sites can't reach.
The pattern exists. Most of it is accidental. The proposal is to do it deliberately.
What is Academic Citation Infrastructure?
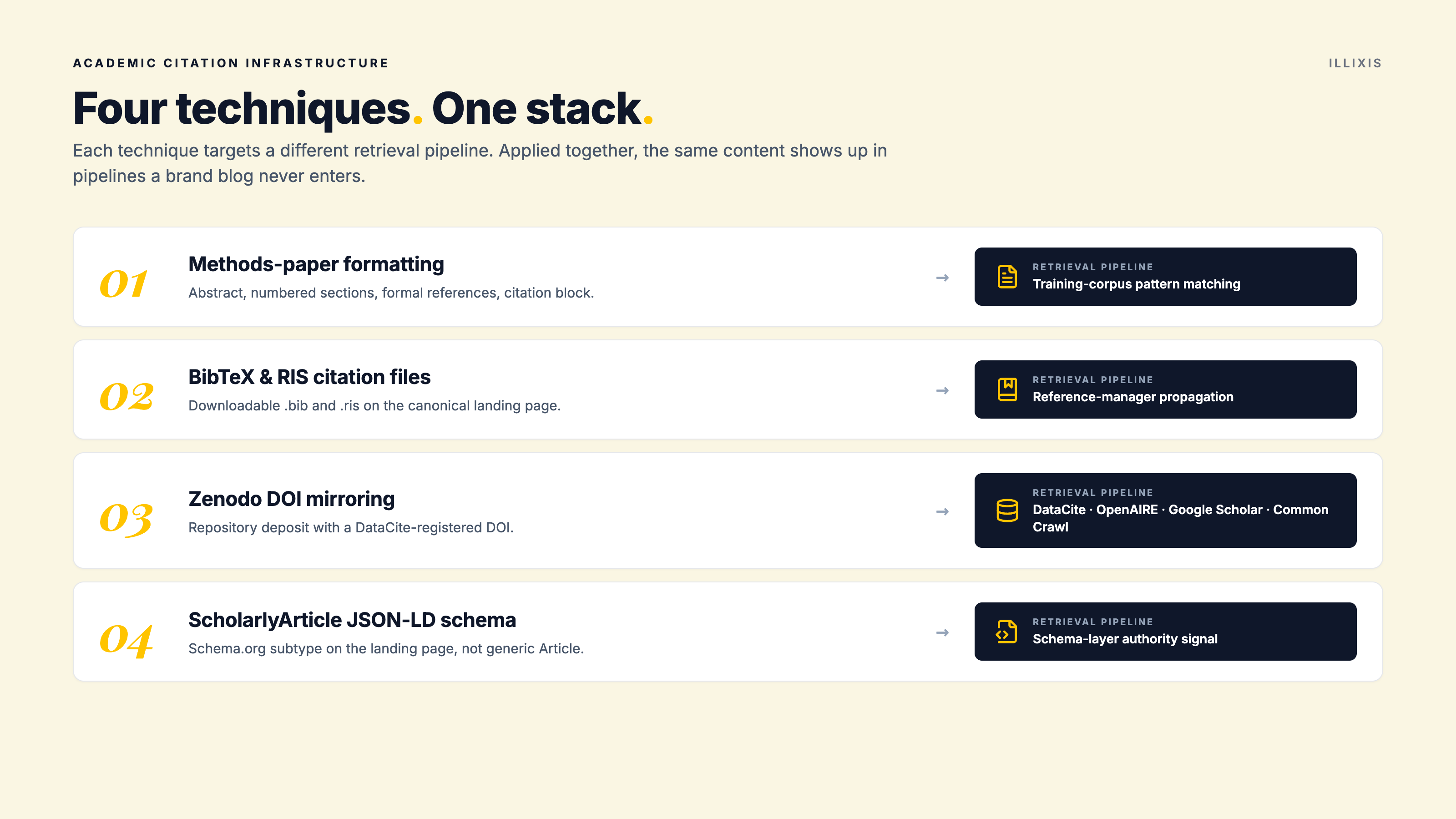
ACI is the deliberate attachment of scholarly publishing infrastructure to commercial content. Four techniques unify into a coherent strategy:
1. Methods-paper formatting. Structure a piece of commercial research as a methods paper would be structured: abstract, numbered sections, formal references, named framework, citation block at the bottom. This is a content-level intervention, but the structure is what AI systems learned during training to associate with citation-worthiness.
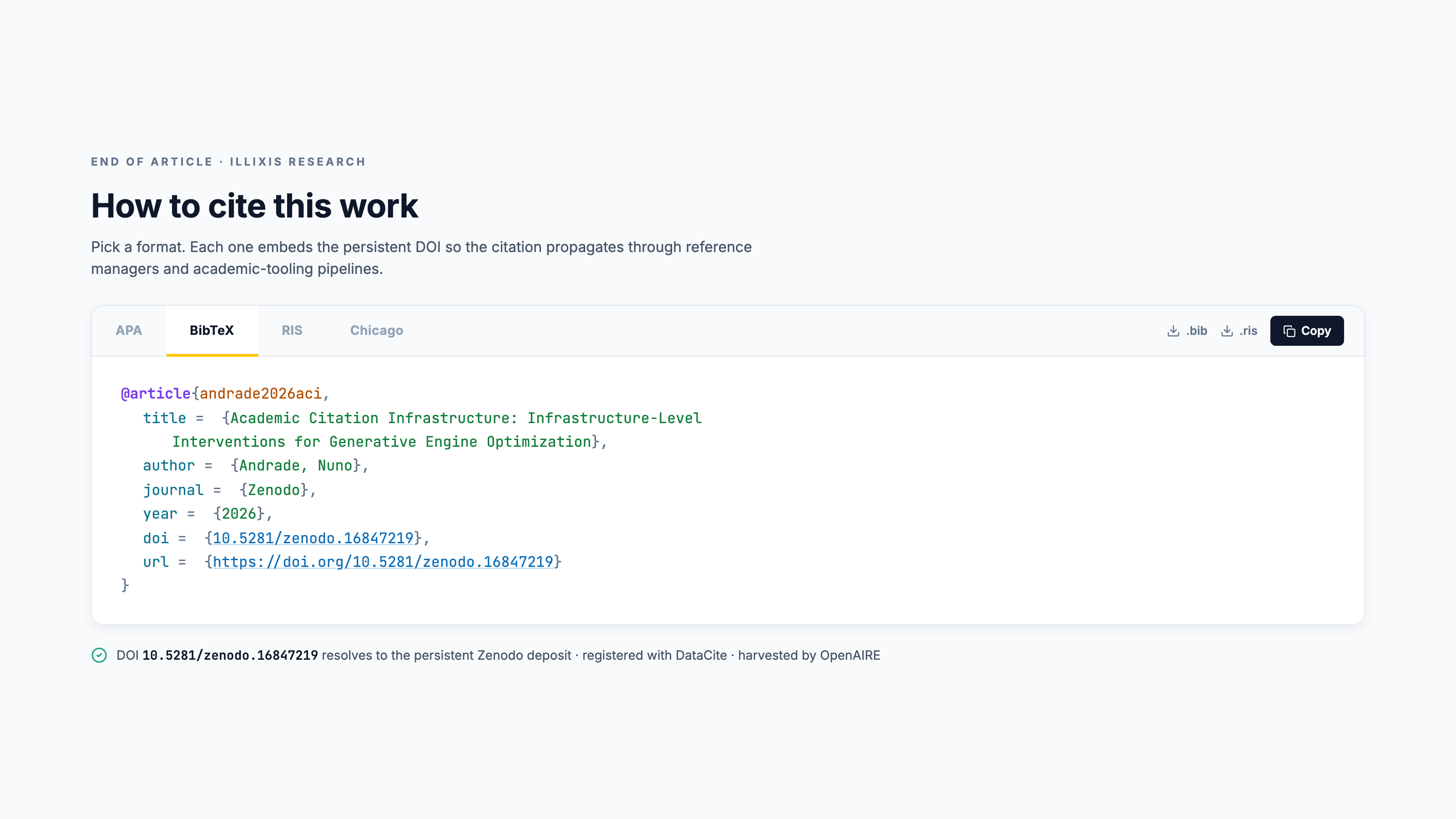
2. BibTeX and RIS citation files. Provide downloadable .bib and .ris files on the canonical landing page. These are how citations propagate through academic tooling. When a reference manager imports a citation, it imports the BibTeX entry, including any embedded DOI. Friction matters: if it's hard to cite, it doesn't get cited.
3. Zenodo DOI mirroring. Deposit the canonical piece on Zenodo (or Figshare, or another DataCite-registering repository) with a DOI. This puts the content inside the DataCite registry, which is harvested by OpenAIRE, indexed by Google Scholar, and crawled by Common Crawl. It also creates a second canonical-equivalent URL that can appear in a different fan-out sub-query than your blog.
4. ScholarlyArticle JSON-LD schema. Use the ScholarlyArticle schema subtype on the canonical landing page, not the generic Article or BlogPosting. This is the schema layer's signal of academic-tier content. Vendor blogs and AI-system practitioner guides are converging on this typing recommendation, and the methods paper documents the convergence across at least six independent practitioner sources. (Google's own AI documentation notes that schema markup isn't required for generative AI search, which is permissive rather than prohibitive. Notably, in chatbot testing, ChatGPT independently surfaced "ScholarlyArticle" by name as a recommended GEO tactic without being prompted to consider schema.)
These work as a stack. Each technique targets a different pipeline. The methods paper makes the mechanism precise for each one.
Four techniques. One stack. Each one targets a different retrieval pipeline.
How to start
Pick one piece of content. Not a blog post. A piece of commercial research worth treating as a methods paper. A market analysis, a product technical note, a benchmark study, a framework document, a defensive disclosure. Something that has a thesis, evidence, and a recommendation.
Week 1: Restructure the canonical version.
- Add an abstract and numbered sections.
- Add a formal references list. Cite specific studies with DOIs, not just blog links.
- Add a citation block at the bottom in three formats minimum: APA, BibTeX, RIS.
- Add a "How to cite" instruction.
Week 2: Add the infrastructure layer.
- Generate downloadable
.biband.risfiles. Embed the canonical URL in both. - Apply
ScholarlyArticleJSON-LD schema on the landing page. Includeauthor,datePublished,headline, and acitationarray if you reference other works. - Make sure the page is text-selectable HTML, not an image or a PDF embed only. Retrieval pipelines parse HTML; they don't parse PDFs reliably.
Week 3: Deposit on Zenodo.
- Create a Zenodo account, linked to an ORCID iD (both free, no review queue).
- Upload the canonical PDF and any supplementary materials. Use the same title and abstract as the canonical version.
- Mint the DOI. Update the BibTeX and RIS files to embed the new DOI. Update the canonical landing page to reference the Zenodo deposit.
Week 4: Measure and iterate.
- Record current citation rate by asking the major AI systems about your topic. Note which sources they cite.
- Re-test in 30 days. Look for: the piece appearing in cited URLs, your brand surfacing in adjacent fan-out queries, the Zenodo deposit accumulating views.
- The methods paper proposes a more formal experimental design for teams that want one.
One piece of content done all four ways is the right unit of work. Doing all four techniques on one piece is more informative than doing one technique on four pieces. The methods paper's experimental design uses exactly that variant structure for the same reason.
Same content. New infrastructure.
GEO research so far has focused almost entirely on content-level interventions: write better, structure tighter, cite more. Those interventions matter. The methods paper does not dispute them. But they all operate at the what the page says layer.
ACI operates at the what the page is wrapped in layer. The same content, deposited on Zenodo with a DOI and a BibTeX file and ScholarlyArticle schema, enters a different set of pipelines than the same content sitting alone on a blog. It doesn't need to be a different piece. It needs to be the same piece in more places, wrapped in the metadata those places expect.
The brands already doing this got there by accident. The methodology proposes you do it on purpose, with a clear theory of why each technique works.
Where to go deeper
Read the methods paper for the formal framework, the four mechanisms, the supporting research, the 15+ deposit catalog, the proposed experimental design, and the references with verified DOIs.
See the ACI Playbook for operational templates, schema examples, BibTeX generators, the Zenodo deposit checklist, and the week-by-week implementation guide.
Pick one piece. Do all four things. See where it shows up in 30 days.
The infrastructure already exists. The pipelines already work. The brands that learn to use them get cited.
Written by Nuno Andrade, founder of ILLIXIS.
This article is the accessible companion to the methods paper Academic Citation Infrastructure: Infrastructure-Level Interventions for Generative Engine Optimization, published 2026-05-26 on Zenodo with DOI 10.5281/zenodo.20401793.
